
Zeta AI
Master new opportunities and tackle your toughest business challenges with ZOE™ generative AI powering the Zeta Marketing Platform’s future.

The generative AI revolution is happening now. Native to the Zeta Marketing Platform, the Zeta Opportunity Engine (ZOE) unlocks bold new capabilities when it comes to creativity, automation, optimization, and forecasting. But the possibilities don’t stop there, as ZOE is leading the way to breakthrough customer experiences, bolder strategies, and bigger and better outcomes.

Virtual assistants at your fingertips
No matter your role—Business Analyst, Campaign Manager, Media Strategist, Merchandiser —ZOE acts as an extension of your team combining first- party data and Zeta’s proprietary data to experience and learn, recommend targetable audiences, and create highly individualized experiences optimized to produce accelerated results.
Identify targetable audiences and personas using ZOE’s proprietary signals and insights
Automate onboarding, A/B/n testing, subject line testing, creative input, and more
Generate custom reports instantly without requiring assistance from developers

Unlock the answers you seek
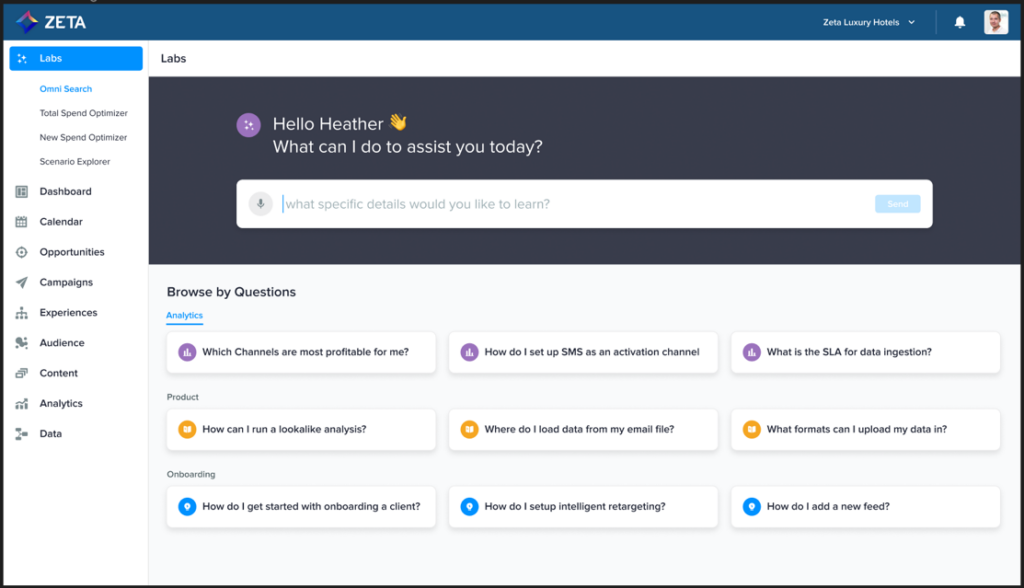
Integrating generative AI with Zeta’s proprietary Data Cloud has unlocked Agile Intelligence, a powerful solution available within the Zeta Marketing Plaform. Find the answers to your most challenging business questions simply by asking them, thanks to NLP. With generative AI at its core, Agile Intelligence understands the intent behind every request:
“Which of my marketing channels is most profitable?”
“Identify the most profitable audience for this product.”
“What is the revenue forecast for campaigns in May?”
"Where should we open our next retail store location?”

Forecast results with speed and accuracy
No more spending hours, sometimes days to forecast revenue with limited visibility and lingering questions. Generative AI produces forecasted results based on bespoke predictions and specific strategies you identify, in real time. Build confidence in your future programs with the ability to forecast revenue, channel profitability, audience engagement, and more.


Related Products and Solutions

Zeta Data
Enrich your knowledge of customers and prospects with insights only Zeta can provide

Agile Intelligence
Data and AI come together to deliver true customer intelligence and solve complex business problems with unprecedented speed and scale.
Zeta Marketing Platform
Create individualized experiences and drive outcomes throughout the customer lifecycle.

